这部分首先介绍语言模型,通过分析传统语言模型的问题引入循环神经网络(Recurrent Neural Network, RNN)以及 RNN的扩展(双向RNN,深度RNN),最后为了改善RNN对长距依存信息的捕获引入GRU(Gated Recurrent Units)和 LSTM(Long-Short-Term-Memories)。
语言模型
这里将介绍传统的n-gram语言模型,然后简单介绍神经概率语言模型,最后总结两者的问题所在引出循环神经网络。
语言模型通常用来衡量一个单词序列出现的概率。假设词序列为\(\{w_1,\ldots,w_T\}\), 那么把这个序列出现的概率记为\(P(w_1,\ldots,w_T)\),计算词序列的概率在机器翻译中有着重要用途, 机器翻译需要给各个候选的词序列打分,这个分数可以用这个概率来衡量。 \(P(w_1,\ldots,w_T)\)的计算可以用链式法则展开:
这个概率估计起来比较复杂(因为\(w_i\)出现的概率依赖于\(w_i\)之前所有的词), 一般进行马尔可夫假设(假设\(w_i\)出现的概率仅依赖\(w_i\)之前的\(n-1\)个词,称为为n-gram)。
一般来说通过语料我们就可以估计出n-gram的概率,下面分别是bigram(2-gram)和trigram(3-gram)的概率计算方法:
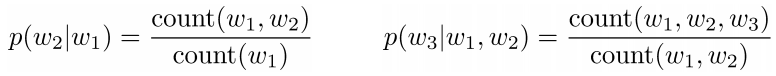 \(n\)越大估计出来的序列的概率越准确,但是这种方法需要大量的内存,假设我们不做任何优化且词表大小为\(|V|\),
那么对于n-gram,需要一个\(|V|^n\)规模的矩阵来存储,需要的内存随着\(n\)增大指数增长,一般5-gram已经是非常大的规模(Google提供)。
\(n\)越大估计出来的序列的概率越准确,但是这种方法需要大量的内存,假设我们不做任何优化且词表大小为\(|V|\),
那么对于n-gram,需要一个\(|V|^n\)规模的矩阵来存储,需要的内存随着\(n\)增大指数增长,一般5-gram已经是非常大的规模(Google提供)。
Bengio等人利用神经网络来表示语言模型,在语言模型的训练过程中可以得到单词的分布式表示,具体的神经概率语言模型图如下:
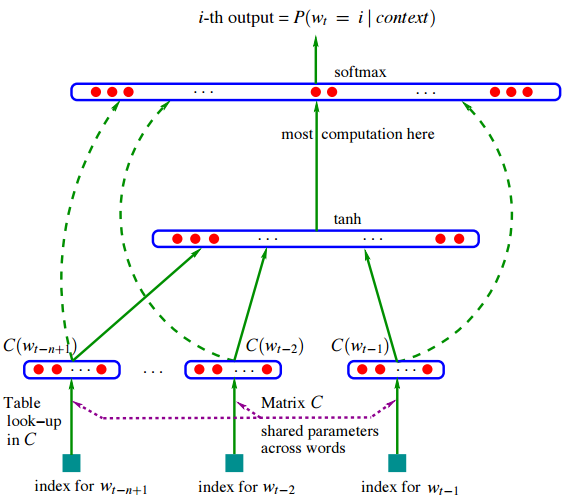 该网络的主要思想是用前\(n-1\)个词的向量来估计当前词的概率,具体公式为:
该网络的主要思想是用前\(n-1\)个词的向量来估计当前词的概率,具体公式为:
可以看出传统语言模型在估计概率的时候需要固定\(n\)的大小,否则无法统计概率\(P(w_i|w_{i-(n-1)},\ldots,w_{i-1})\)。 而RNN的最大优势在于可以统计\(P(w_i|w_1,\ldots,w_{i-1})\)的概率。
循环神经网络(Recurrent Neural Network, RNN)
RNN的优势在于当前词的概率依赖于之前出现的所有词,并且需要的内存并不会随着依赖的上下文长度增加而指数增长,
需要的内存和词表大小规模相关。RNN的网络结构图如下:
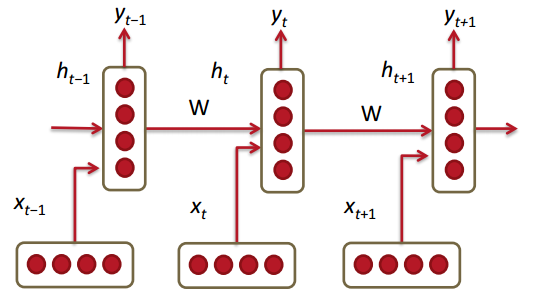 可以看出RNN是一个序列模型,比较符合认知上人理解句子的顺序(从左到右)。在时刻\(t\),将\(t-1\)
时刻的隐藏层输出\(h_{t-1}\)和当前时刻的词向量\(x_t\)输入隐藏层之后得到\(t\)时刻的特征表示\(h_t\),
然后用这个特征表示得到\(t\)时刻的预测输出\(\hat{y}\)。本节的重点是将RNN应用于语言模型,
下面来详细描述RNN语言模型中用到的参数:
可以看出RNN是一个序列模型,比较符合认知上人理解句子的顺序(从左到右)。在时刻\(t\),将\(t-1\)
时刻的隐藏层输出\(h_{t-1}\)和当前时刻的词向量\(x_t\)输入隐藏层之后得到\(t\)时刻的特征表示\(h_t\),
然后用这个特征表示得到\(t\)时刻的预测输出\(\hat{y}\)。本节的重点是将RNN应用于语言模型,
下面来详细描述RNN语言模型中用到的参数:
- \(x_1,\ldots,x_{t-1},x_t,x_{t+1},\ldots,x_T\):\(T\)长度的单词序列中每个时刻的词对应的词向量。
- \(h_t=\sigma(W^{(hh)}h_{t-1}+W^{(hx)}x_t)\):如何计算\(t\)时刻的隐藏层输出:
- \(x_t\in\mathbb{R}^d\):\(t\)时刻的单词对应的词向量
- \(W^{(hx)}\in\mathbb{R}^{D_h\times d}\):连接当前隐藏层和\(x_t\)的权重矩阵
- \(W^{(hh)}\in\mathbb{R}^{D_h\times D_h}\):连接当前隐藏和前一个时刻隐藏层输出\(h_{t-1}\)的权重矩阵
- \(h_{t-1}\in\mathbb{R}^{D_h}\):表示\(t-1\)时刻隐藏层的输出,\(h_0\in\mathbb{R}^{D_h}\)表示\(t=0\)时刻随机初始化的隐藏层输出向量
- \(\sigma()\):表示神经元使用的非线性函数为sigmoid,当然也可以采用tanh等函数
- \(\hat{y}_t=\text{softmax}(W^{(S)}h_t)\):根据\(t\)时刻的隐藏层输出进行softmax分类得到整个词汇表上的概率分布, 这里的\(\hat{y}_t\)是对下个时刻(\(t+1\))词的预测,即根据已经给定的上下文信息\(h_{t-1}\)和当前观测到的词向量\(x_t\) 来预测\(t+1\)时刻的词。其中\(W^{(S)}\in\mathbb{R}^{|V|\times D_h}\),\(\hat{y}_t\in \mathbb{R}^{|V|}\),\(|V|\)为词表大小。
- \(\hat{P}(x_{t+1}=v_j|x_t,\ldots,x_1)=\hat{y}_{t,j}\)
RNN语言模型中非常关键的一点是每个时刻采用的\(W\)矩阵都是一个,所以参数规模不会随着依赖上下文的长度增加而指数增长。 通常来说采用交叉熵作为损失函数,那么在\(t\)时刻的损失为:
在一个长度为\(T\)的序列上的总交叉熵为:
用来衡量语言模型的一个常用指标是困惑度(perplexity),困惑度越低表示预测下个词的置信度越高,困惑度和交叉熵的关系如下:
RNN语言模型需要的内存正比于序列长度,因为需要将这个序列的词向量存储在内存中。
RNN训练
其实RNN本质上还是一个普通的多层神经网络,只是层与层之间使用的是同一个权重矩阵而已, 同样可以利用上一篇文章介绍的后向误差传播的原理来进行后向误差传播, 只需要把\(t\)时刻的误差一直传播到\(t=0\)时刻,但是在实际实现的时候一般只需要向后传播\(\tau\approx 3-5\)个时间单位。
对于\(t\)时刻需要求的梯度如下:
其中\(|_t\)表示求\(t\)某个参数的梯度,因为\(W^{^(hh)}\)和\(W^{(hx)}\)两个参数在不同时刻用到, 需要求出不同时刻两个矩阵的梯度,然后进行累加。
对于\(t-1,\ldots,t-(\tau - 1)\)时刻需要求的梯度如下:
这里以RNN语言模型为例,将\(t\)时刻的RNN展开一个多层神经网络,其中包含一个softmax层,进行后向传播,示意图如下:

假设\(a_t=W^{(S)}h_t\),那么\(\hat{y}_t=\text{softmax}(a_t)\),根据之前文章可知 \(J^{(t)}\)相对于\(a_t\)的梯度为:
\(J^{(t)}\)相对于\(W^{(S)}\)的梯度如下:
假设\(z_t=W^{(hh)}h_{t-1}+W^{(hx)}x_t\),那么\(h_t=\sigma(z_t)\),现在我们需要把\(a_t\)处的误差传播到\(z_t\)处, 其实就是上一篇文章如何从\(\delta^{(t+1)}\)得到\(\delta^{(t)}\), \(z_t\)的误差如下:
类似地可知\(J^{(t)}\)相对于\(t\)时刻\(W^{(hh)}\)的梯度如下:
\(J^{(t)}\)相对于\(t\)时刻\(W^{(hx)}\)的梯度如下:
\(J^{(t)}\)相对于\(x_t\)的梯度如下:
对于\(t-s\)时刻来说,首先我们要得到\(z_{t-s}\)处的误差,计算如下:
得到\(\delta_{t-s}\),求解 \(\left. \frac{\partial{J^{(t)}}}{\partial{W^{(hh)}}}\right|_{t-s}\), \(\left. \frac{\partial{J^{(t)}}}{\partial{W^{(hx)}}}\right|_{t-s}\)和 \(\frac{\partial{J^{(t)}}}{\partial{x_{t-s}}}\) 都和\(t\)时刻一致,直接表示成\(\delta_{t-s}\)的式子。
梯度消失(vanishing gradient)和梯度爆炸(exploding gradient)
当我们把\(t\)时刻的误差往后传播的时候就可以得到\(J^{(t)}\)对于各个参数的梯度, 在这个后向传播的过程中我们为了方便计算\(t-s\)时刻的梯度引入了\(\delta_{t-s}\), 式\(\ref{eq:delta_bp}\)是根据\(\delta_{t-s+1}\)计算\(\delta_{t-s}\)的公式,可以改写成:
简化之后写成下面式子
假设\({(W^{(hh)})}^T\)和\(\text{diag}[f'(z_{t-s})]\)的范数上限分别为\(\beta_W\)和\(\beta_z\),那么:
那么可以看出\(t\)时刻\(z_t\)处的误差\(\delta_t\)后向传播到\(t-s\)时刻\(\delta_{t-s}\)的误差有下面关系:
可以看出\(\delta_{t-s}\)随着\(s\)增大会迅速增大或者减小,这种现象称为梯度爆炸或梯度消失。
以语言模型为例来看一下梯度消失带来的问题,本来引入RNN的目的是为了能够表示长距离的上下文信息。
例如下面两个句子,我们要用已有的上下文信息预测句子的最后一个词:
 可以看出根据上下文信息,这个句子的答案应该都是“John”。理想状态下RNN应该也应该能够根据上下文中信息预测出下个词应该是“John”,
因为这个词在之前在上下文中出现过。但是实际情况是对于第一个句子RNN更容易预测正确,这是因为在后向误差传播过程中,
梯度传播到比较早的时刻就逐渐消失了。对于较长的句子(第二个句子),与答案有关的信息距离最后那个时刻比较远, 对预测答案的贡献很小,所以容易出错。
可以看出根据上下文信息,这个句子的答案应该都是“John”。理想状态下RNN应该也应该能够根据上下文中信息预测出下个词应该是“John”,
因为这个词在之前在上下文中出现过。但是实际情况是对于第一个句子RNN更容易预测正确,这是因为在后向误差传播过程中,
梯度传播到比较早的时刻就逐渐消失了。对于较长的句子(第二个句子),与答案有关的信息距离最后那个时刻比较远, 对预测答案的贡献很小,所以容易出错。
为了解决梯度爆炸问题,Mikolov提出了一种启发式的解决方法,当梯度超过一个阈值的时候,将梯度裁剪到一个合适的值,算法流程如下:

对于梯度消失问题,这里介绍两个方法。第一个方法是将\(W^{(hh)}\)初始化称一个单位矩;第二个方法是使用ReLU神经元, 因为这个神经元的局部梯度要不是0就是1,这样后向传播经过神经元的时候误差不会变小。
双向RNN和深度双向RNN
单向RNN的问题在于\(t\)时刻进行分类的时候只能利用\(t\)时刻之前的信息,
但是在\(t\)时刻进行分类的时候可能也需要利用未来时刻的信息。双向RNN(bi-directional RNN)模型正是为了解决这个问题,
双向RNN在任意时刻\(t\)都保持两个隐藏层,一个隐藏层用于从左往右的信息传播记作\(\overrightarrow{h}_t\),
另一个隐藏层用于从右往左的信息传播记作\(\overleftarrow{h}_t\)。
双向RNN模型需要的内存是单向RNN的两倍,因为在每个时间点需要保存两个隐藏层,还需要保存从右往左方向的相关权重矩阵。
在\(t\)时刻进行分类的时候同时使用两个隐藏层的信息作为输入进行分类,下图为网络结果示意:
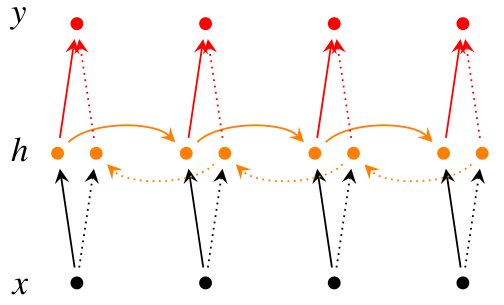 下面是\(t\)时刻两个隐藏层的计算方法,两个公式的区别仅仅在于计算方向不同:
下面是\(t\)时刻两个隐藏层的计算方法,两个公式的区别仅仅在于计算方向不同:
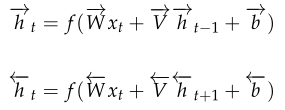 最后利用\(t\)时刻的两个隐藏层信息进行分类,如下式:
最后利用\(t\)时刻的两个隐藏层信息进行分类,如下式:
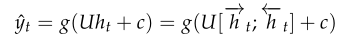 此时式中的\(h_t\)同时表示了词左边和右边的上下文信息。
此时式中的\(h_t\)同时表示了词左边和右边的上下文信息。
有了单层的双向RNN之后,可以构建深度双向RNN,下图为多层双向RNN的网络结构图:
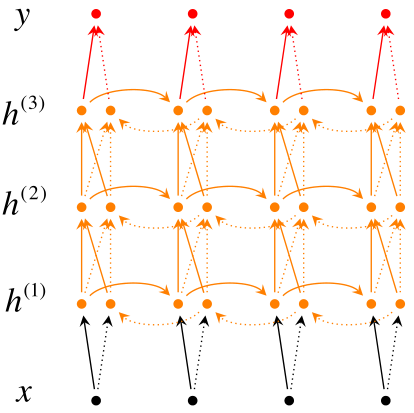 可以看出\(t\)时刻计算第\(i\)层从左往右传播的隐藏层信息\(\overrightarrow{h}_t^{(i)}\)时,输入有两部分,
第一部分是同一层之前一个时刻的隐藏层信息\(\overrightarrow{h}_{t-1}^{(i)}\),
第二部分是前一层同个时刻的两个方向隐藏层信息\(h_t^{(i-1)}=[\overrightarrow{h}_{t}^{(i-1)};\overleftarrow{h}_{t}^{(i-1)}]\)。
下面给出第\(i\)层\(t\)时刻两个隐藏层的计算方法:
可以看出\(t\)时刻计算第\(i\)层从左往右传播的隐藏层信息\(\overrightarrow{h}_t^{(i)}\)时,输入有两部分,
第一部分是同一层之前一个时刻的隐藏层信息\(\overrightarrow{h}_{t-1}^{(i)}\),
第二部分是前一层同个时刻的两个方向隐藏层信息\(h_t^{(i-1)}=[\overrightarrow{h}_{t}^{(i-1)};\overleftarrow{h}_{t}^{(i-1)}]\)。
下面给出第\(i\)层\(t\)时刻两个隐藏层的计算方法:
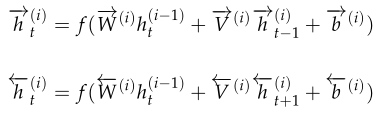 多层的双向RNN利用最后一个隐层的信息进行分类任务,假设深度RNN共有\(L\)个RNN层,深度RNN会利用第\(L\)层的隐藏层信息进行分类任务:
多层的双向RNN利用最后一个隐层的信息进行分类任务,假设深度RNN共有\(L\)个RNN层,深度RNN会利用第\(L\)层的隐藏层信息进行分类任务:
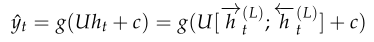
RNN的应用
RNN是一个序列模型,跟CRF类似,可以应用于大量的序列标注问题上。 例如中文分词, 命名实体识别,词情感极性标注,观点挖掘, 机器翻译等。 由于普通RNN的隐藏层无法保存长距离的信息,下篇文章将介绍两种新的RNN隐藏层计算方法来缓解这个问题, 一个是GRU,另一个是LSTM。