这部分内容主要总结Softmax分类,以及如何以交叉熵作为Softmax分类的损失度量标准来 训练Softmax的参数,最后将Softmax分类应用在一个简单的窗口分类任务上,窗口分类 指的是利用中心词向量以及中心词窗口范围内的向量拼接起来对中心词进行简单的分类 (例如把中心词按实体类型分成人名、地名、组织名、其他)。
Softmax分类
Softmax分类是Logistic回归的扩展版(Logistic回归用于二分类,Softmax分类用于类别 数量>2的分类任务),词向量\(x\)(假设词向量维度是\(d\))属于类别\(j\)的概率如下所示:
其中\(W\in\mathbb{R}^{C\times d}\),\(W_{j\cdot}x=\sum_{i=1}^d W_{ji}x_i=f_j\)。 以交叉熵作为损失函数,可以得到对于特定一个训练样本的损失如下:
由于\(y\)是一个one-hot向量,所以\(y\)有\(C-1\)个值为0,假设\(y_k=1\),那么上式可以写成:
如果有\(N\)个数据点,那么总的损失如下:
其中\(k(i)\)代表第\(i\)个数据点正确的类别标签。
这里有一个地方需要注意,就是我们把利用softmax对词向量分类的时候是否需要对词向量进行更新。
如果不需要更新词向量那么此时参数只有\(W\)矩阵,参数规模为\(C\cdot d\);但是如果需要对词向量进行更新,
那么模型的参数就会变多,因为我们需要对词汇表中的向量进行更新,总的模型参数变成\(C\cdot d + |V|\cdot d\)。
假设用\(\theta\)表示模型参数,此时损失函数对于\(\theta\)的导数如下:
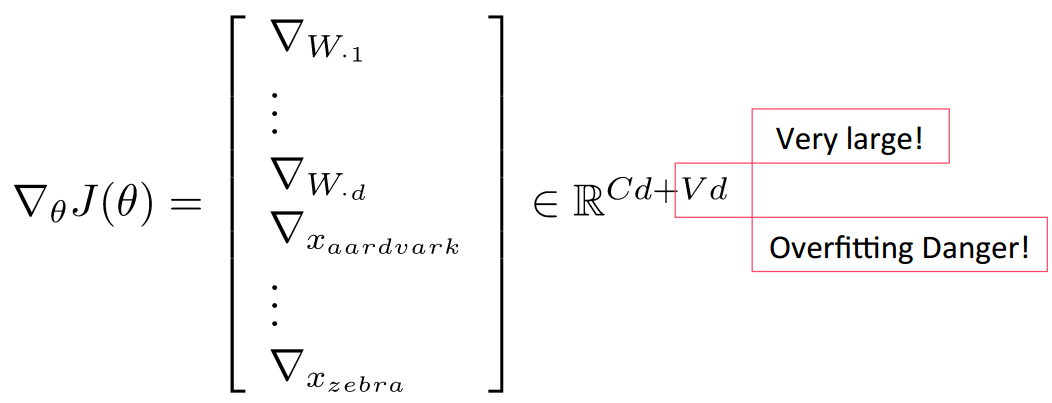 如此大的参数规模很容易导致模型过拟合,可以通过加入\(L2\)正则来减缓过拟合(使得模型参数接近0):
如此大的参数规模很容易导致模型过拟合,可以通过加入\(L2\)正则来减缓过拟合(使得模型参数接近0):
这里对于单个训练样本的交叉熵损失进行一个初步的导数推导,假设该样本类比为k:
求导结果如下:
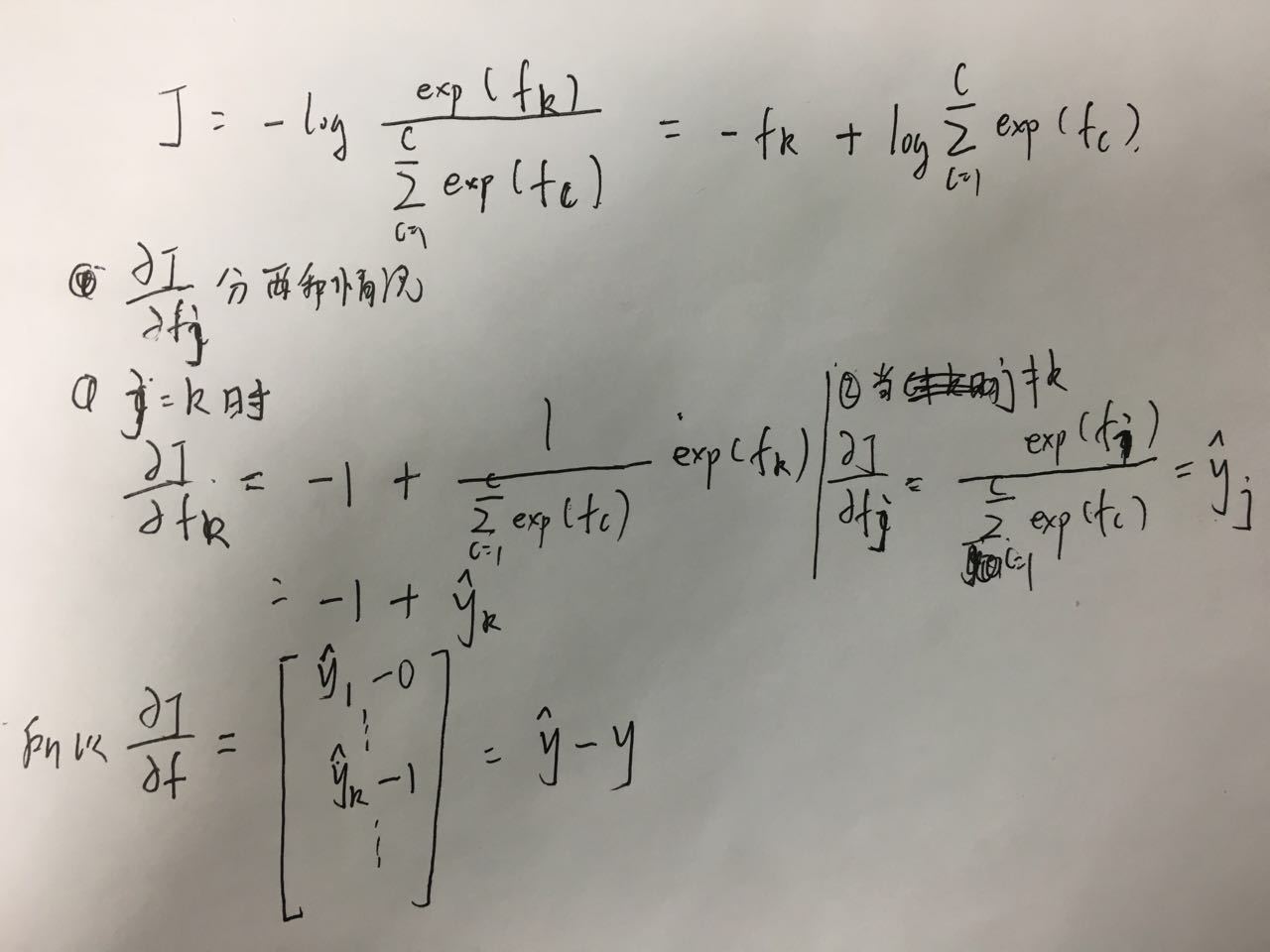
窗口分类
窗口分类指的是利用中心词向量以及中心词窗口范围内的向量拼接起来对中心词进行简单的分类
(例如把中心词按实体类型分成人名、地名、组织名、其他)。下面例子取窗口长度为2,
对中心词“Paris”进行分类,最后令输入向量\(x_{\text{windows}}=x\in \mathbb{R}^{5\cdot d}\)
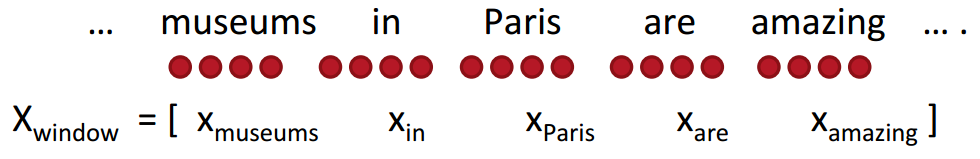
整个模型就是一个简单的softmax分类,所以我们只要把softmax的损失函数对\(W\)和\(x\)求导就可以
得到梯度,其实求导结果和上一篇文章相同,
由于两篇文章在符号表示上略有区别,这里按这篇文章的符号重新推导一次,最后的结果是相同的。
下一篇文章将介绍神经网络,通过神经网络的后向误差传播过程可以更好地理解这个推导结果。
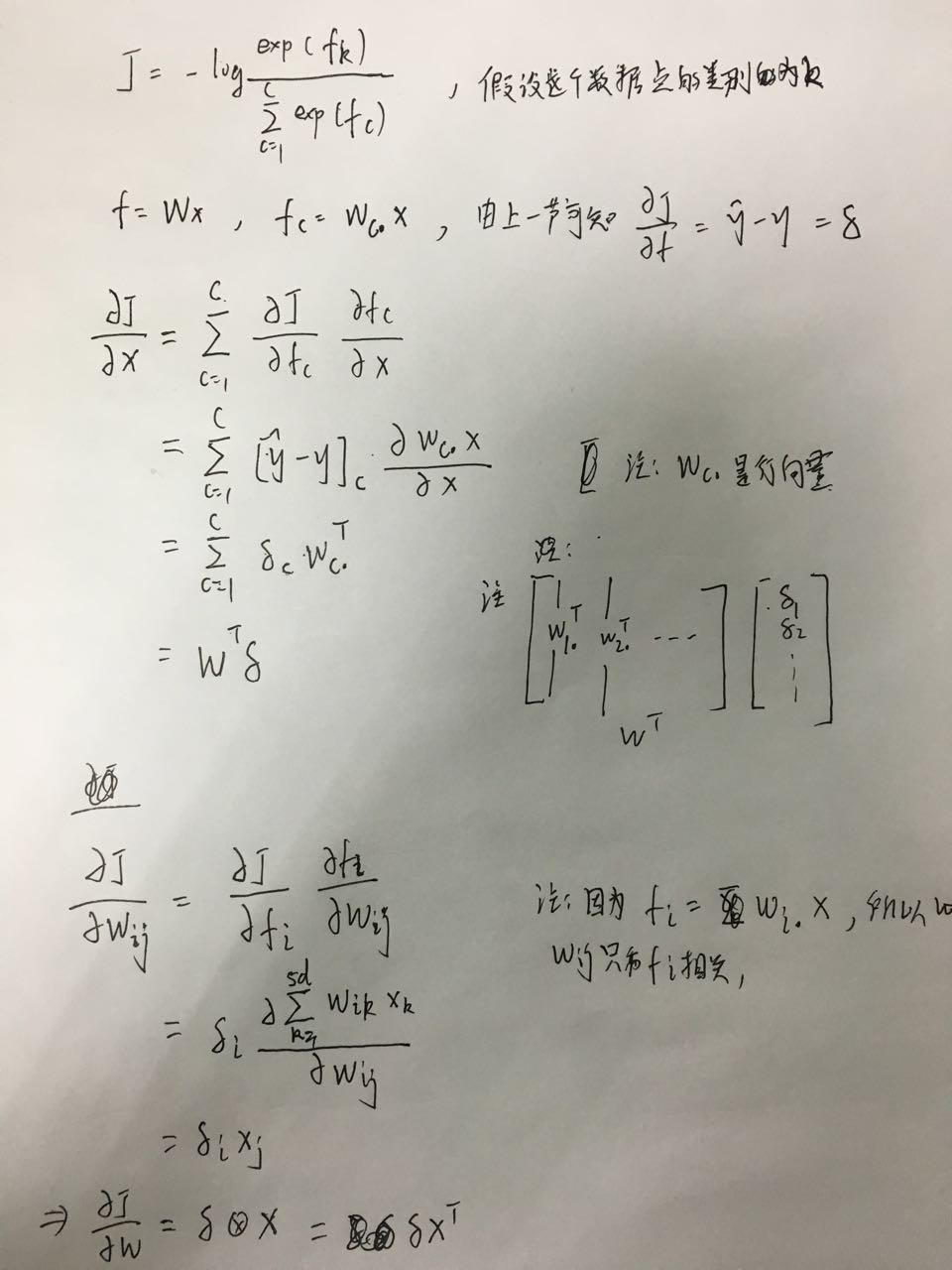
最后把\(x\)上的梯度分配给对应的词向量就可以更新词向量了。

总结
Softmax分类最后得到的只是原始数据空间上的线性分类面,利用神经网络可以学习到非线性的决策边界, 将在下一篇笔记总结神经网络。