1 概述
最近做了一个简单的文本分类程序,在这篇博客里面记录具体的分类流程。一般来说包括 以下几个步骤:
- 语料获取
- 文本预处理
- 特征值提取
- 训练分类器
- 评估分类性能
下文将分析上面每个步骤的具体实现过程。
2 语料获取
语料获取可以采用爬虫来获得,在实现的过程中从网易上获取了十个类别的新闻语料,分
别是:时政、军事、教育、娱乐、房产、女人、财经、体育、科技和旅游。关于爬虫怎么
写可以参考Scrapy 轻松定制网络爬虫,这篇文章对于学习Scrapy框架非常有
用,但是文章较老,很多接口可能很多都被丢弃,新的接口参考Scrapy
Tutorial。如果实在懒得爬
语料可以用我获取好的数据,对数据做一个简单说明,总共有测试语料10万篇,每种新闻
各1万篇;测试语料1万篇,每种新闻1千篇,点击这里
下载,语料示例如下,URL::和END之间是一篇文章:
URL::http://politics.people.com.cn/n/2012/1120/c14562-19635416.html 2012-11-20
贵州毕节5名男孩取暖致死 副区长等8人被免职
“中国网事”记者获悉,毕节市委19日晚研究决定,对5名男孩意外死亡事件负有领导和管理责任的七星关区分管民政工作的副区长唐兴全、分管教育工作的副区长高守军等8人分别进行停职或免职处理。(记者王丽)
END::
3 语料预处理
得到语料之后需要对语料做预处理,预处理的过程包括:分词、去停用词、去低频词等。
3.1 分词和去停用词
现在有很多可以免费使用的分词工具,包括:
本文使用的是FudanNLP中文自然语言处理工具包,如何分词请参考 QuickStart和 APIDoc,由于代码比较多,文章中仅仅贴出部分函数代码:
public void doSeg(String infile, String outfile) throws IOException {
// 切分一个大文件很消耗时间
// 因此如果输出文件存在就抛出异常
// 让用户确保不会产生覆盖文件
if (new File(outfile).exists())
throw new IOException(outfile + " is existed");
LineIterator it = FileUtils.lineIterator(new File(infile), encoding);
BufferedWriter bw = null;
try {
bw = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(outfile), encoding));
StringBuilder stringBuilder = new StringBuilder();
while (it.hasNext()) {
String line = it.nextLine().trim();
if (line.isEmpty() || line.startsWith("URL::"))
continue;
if (line.startsWith("END::")){
stringBuilder.append("\n");
bw.write(stringBuilder.toString());
stringBuilder = new StringBuilder();
continue;
}
// seg line
String[] words = segTagger.tag2Array(line);
// 对分词的结果去除停用词
List<String> baseWords = stopWords.phraseDel(words);
stringBuilder.append(Joiner.on(" ").join(baseWords));
stringBuilder.append(" ");
}
} finally {
it.close();
if (bw != null) {
bw.close();
}
}
}
上述代码中通过segTagger.tag2Array(line)分词,得到的分词结果是一个数组,再对分
词的结果去除停用词stopWords.phraseDel(words)。这里的segTagger和stopWords
都是有FudanNLP提供的类。在语料中,一篇文章的正文是URL::和END::
之间的部分,代码中逐行分词,然后把分词和去停用词的多行合并成一行,最后得到的一 篇文章就是一行。
3.2 去除低频词
通过分词和去除停用词之后,语料库中的词汇表规模(不同的词的数目)还是非常的大,
10万篇语料处理之后,词汇表有69万个词。这么大的词汇表对于后面我们计算特征值非常
不利,例如用最简单的TF(term frequency)计算特征,要把每篇文章转换成一个词频向
量,而这个向量的长度就是我们的词汇表大小,如果这个表太大的话,会有很多词频为0,
直接导致数据稀疏问题,而且也会有很多噪声。从词汇表里面去除一些词的方法,最简单 的是采用词频过滤,即词频低于多少的词就忽略,下面描述具体做法。
首先,我们要在整个训练集合上统计所有词的频率分布,这里用JAVA的HashMap就能实
现,以词为键,词出现的次数(词频)为值,整个语料库遍历之后,就得到每个词分别在
语料库里面出现多少次,最后对这个HashMap做一个按值降序排序,越早出现的词那么词
频就越高。下图是我统计的一个累计词频分布图,累积地统计个词的出现次数占总次数的
比例,发现少部分词占有了大部分的词频。更多有意思的词频规律参考
Zipf’s law。
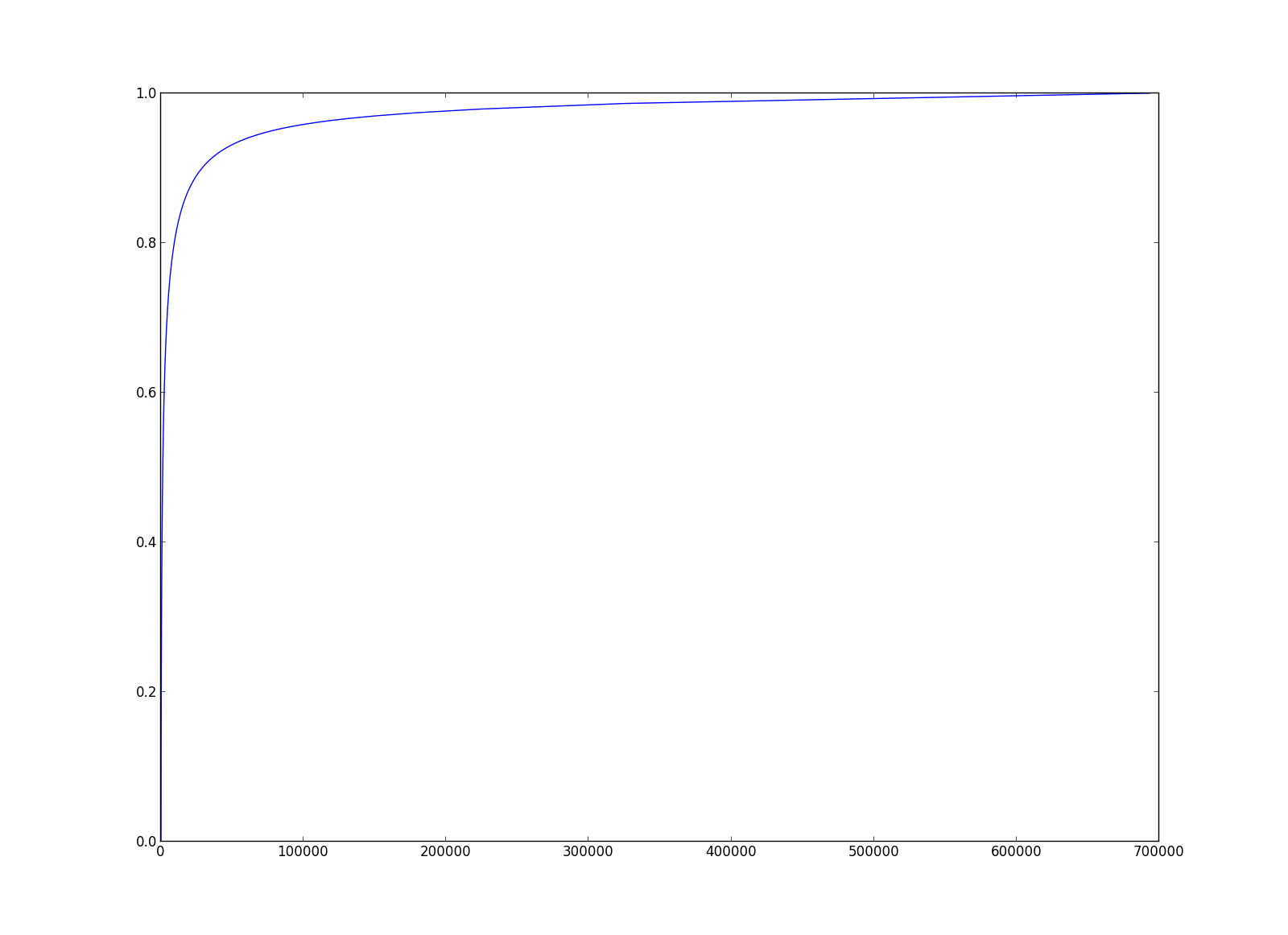
本文最终取前3万个词频最高的词作为词汇表,这3万个词,总的出现次数已经占到总次数 的90%。当然从词汇表里面去除一些词还有更高级的做法,例如:计算每个词对整个语料库 的信息增益,取信息增益最高的多少个词作为词汇表,信息增益是什么,请参考这里 ,具体实现 参考这里;也可以 用TF-IDF来度量词的重要性。
4 特征提取
特征提取的目地是把文本转换成特征向量,为后面的分类器训练做数据准备。最经典的方 法应该就是向量空间模型 ,更复杂的方法可以用 LDA等。下面分 别介绍向量空间模型和LDA。
4.1 向量空间模型
向量空间模型就是把词汇表的每个词都当作特征的一个维度,特征的取值是这个词在这篇
文章中出现的次数。现在假设词汇表有六个词,分别是:上海 海关 建立 任务 提醒 机制
,下面示例如何把文章换转成一个向量,假设语料库里面有两篇文章
\(d_1\)和\(d_2\)
把词汇表的词依次记作: \(w_1\ w_2\ w_3\ w_4\ w_5\ w_6\),就可以统计文章中每个词出 现的次数。以\(d_1\)为例子,在\(d_1\)中,\(w_1\)(上海)出现2次,\(w_2\)出现1次,\(w_3\)出 现1次,\(w_4\)出现1次,\(w_5,w_6\)出现0次,最终向量形式为:
这样就可以把每个文档都转换成一个词频向量,用这个词频向量就可以计算两个文档之间 的相似度,即求两个文档词频向量的余弦相似度,相似度越接近1代表越相似:
当然这里的词频特征也可以用更为合理的IF-IDF特征取代,具体请参考这里
的计算过程。
4.2 用LDA提取特征(OPTIONAL)
其次我们可以使用LDA把每篇文档表示成主题的一个分布,然后用这个主题分布当作特征向
量来训练分类器。可以使用JGibbsLDA将训练语料转换成关于主题的分布。由于我们再预处理步骤已经把每篇预处
理好的文档变成一行,接下来我们就可以把训练语料转换成JGibbsLDA需要的格式。
[M]
[document1]
[document2]
...
[documentM]
[M]表示文档总数,没一行是一篇文档,[documenti]表示语料库里面的第i篇文档,
每篇文档总用有Ni个词:
[documenti] = [wordi1] [wordi2] ... [wordiNi]
用JGibbsLDA训练得到的输出结果中,名为<model_name>.theta的文件包含了每篇文档
的主题分布\(p(topic_t|document_m)\),一行是一个文档,每列是一个主题。
5 训练分类器
得到每个文档的特征向量之后,训练的过程可以采用各种各样的分类器,例如:朴素贝叶 斯、神经网络、SVM等。本文以SVM为例子简要描述一下分类过程,SVM可以使用 LIBSVM这个库。首先要把特征向量整理成LIBSVM的输入格式,然后 再进行训练。
5.1 特征格式转换
由于训练语料里面我们知道每篇文章的类别,因为我们是分文件存储每个类别的文档,可
以把10个类别打上标签0~9,表示用0来表示1类新闻,1来表示另一种新闻,依此类推。
LIBSVM的输入格式如下:
<label> <index1>:<value1> <index2>:<value2> …
…
<label> <index1>:<value1> <index2>:<value2> …
假设我们上面举例的\(d_1\)文档属于0这个标签,\(d_2\)这个文档属于1这个标签,那么这两 篇文档可以表示成如下格式:
5.2 训练
训练过程直接使用LIBSVM的C代码编译好的可执行文件svm-train,训练之
前可以用svm-scale对数据进行归一化,假设整理好的训练语料为train.txt。
# 归一化训练语料
# 把特征取值范围保存到train.range文件,方便对测试语料归一化
./svm-scale -s train.range train.txt > train.scale
# 训练svm模型
# type: C-SVC
# kernel type: radial basis function: exp(-gamma*|u-v|^2)
# gamma: 0.5
# C of C-SVC: 4
# 训练语料: train.scale
# 保存模型: train.scale.model
./svm-train -s 1 -t 2 -g 0.5 -c 4 train.scale train.scale.model
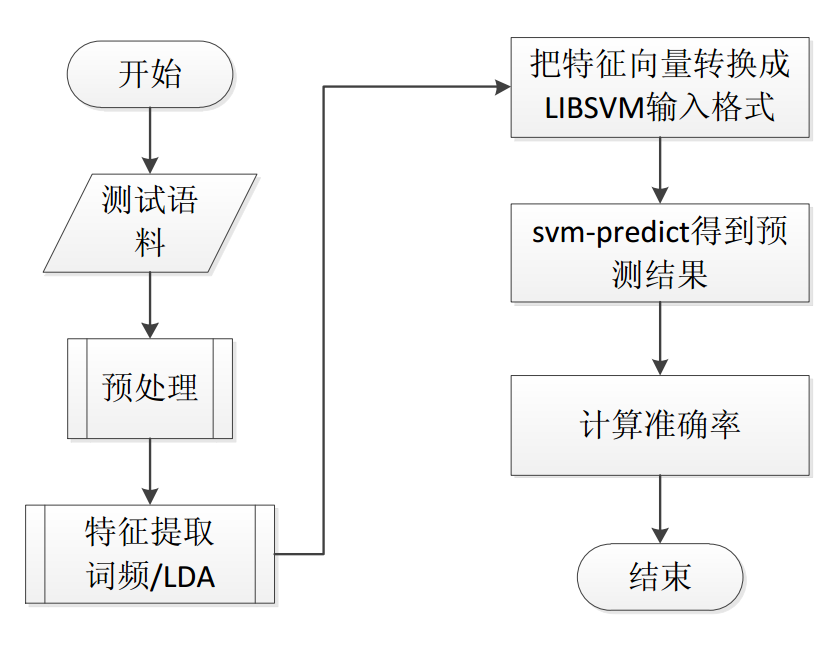
6 测试分类器性能
测试的主要流程如下图,首先也要讲过训练过程的预处理和特征提取,再将特征向量转换
成LIBSVM需要的格式,最后用编译好的svm-predict可执行文件进行分类,最
后取得的准确率为0.8592%。