下面主要是阅读刘铁岩老师的《Learning to Rank for Information Retrieval》的一些 学习笔记。Learning to Ranking指的是根据训练数据用机器学习模型来解决排序问题。很 多IR问题都可以看成是排序问题,例如文档检索、协同过滤、关键词抽取、定义查找,本 文主要以文档检索为例子来描述Learning to Rank。
传统IR模型
传统的IR模型可以分成两类,一类是query-dependent,另一类是query-independent。
query-dependent指的是检索的时候考虑query和doc之间的关心,衡量这个关系的不同方法 产生了不同的模型, 考虑doc和query的相关性:
- Boolean model: 对doc中的term做倒排,然后query是一个boolean表达式,对取回来的 文档集合做交集并集等等
- Vector space model: 把doc和query都表示在一个统一的欧拉空间(每个term一个维度 ),每一个维度的值一般可以是TF-IDF ...
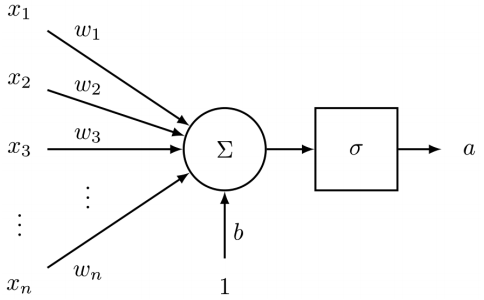 神经元的参数包括一个
神经元的参数包括一个 这两个Loopback一个是麦克风(Loopback from ...
这两个Loopback一个是麦克风(Loopback from ...